
אלגוריתמים בשירות מרחבי - למידת מכונה מאפשרת להפוך מונו בווידאו לתלת-מימד
נכון, 3D בסאונד קיים כבר עשרות שנים, אך חיקוי אפקטיבי לסאונד מרחבי מנותב תמונה תמיד היה אתגר.

ולא, לא מדובר בעוד פלגין שמדמה תמונת סטריאו רחבה (ועתירת בעיות ברוב המקרים), וגם לא ב-3D - הכירו את ה-2.5D החדש!
אם נקשיב לרעשים ורחשים בשטח בעיניים עצומות, נוכל לזהות בקלות אם מקור הצליל מאחורינו, מקדימה, מהצד וכדומה.
יכולת האדם לפענח מיקום של צליל במרחב תלת מימדי היא מדהימה, והיא בין השאר אפשרית בזכות האוזניים בעלות המבנה הסימטרי והמרחק ביניהם, שהן הקולטנים הייחודיים, הגוף, והפענוח במוח.
אך בעוד החוקרים למדו כצד ליצור סאונד 3D הצליח לרמות את מערכת הראיה שלנו, אף אחד לא ממש מצא דרך ליצירת סאונד 3D סינתטי המסוגל לשכנע את מערכת השמע.
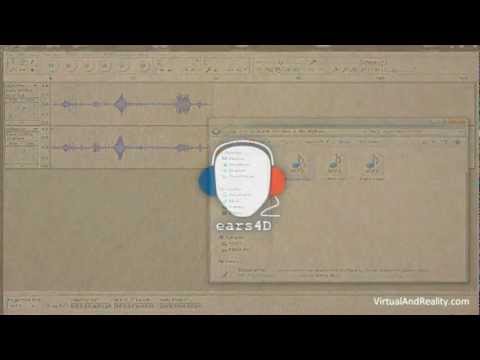
נראה שבעיה זו לפני פתרון, הודות לחוקרים מאוניברסיטת טקסס ומפייסבוק, אשר הצליחו לבנות מערכת למידת מכונה אשר הופכת סאונד מונו לתלת מימד, והם מכנים זאת "סאונד 2.5D".
קצת רקע. המוח עושה שימוש ברמזים שונים כדי לפענח ולקבוע מהיכן מגיע הצליל במרחב התלת מימדי. רמז אחד חשוב הינו המרחק שבין מקור הצליל לכל אוזן בנפרד. הפרשי זמנים ומופע.
רמז נוסף היא העוצמה. אותו הצליל יופיע חזק יותר באוזן אחת מאשר השניה, שוב - בגלל הבדלי המרחק.
שימוש בצמד מיקרופונים תואמים לחיקוי המרחק בין האוזניים לא ממש מפיק את האפקט הזה, כיוון שההפרדה בין המיקרופונים אינה תואמת את מה שקורה באפרכסת, לדוגמה, מבחינת כיווניות, רמת עיוות, מופע... וההשפעה המבנית בתוך האוזן. המוח כן יכול לחוש בהבדלים הקטנטנים שמייצרת כל אוזן, ולייצר חיקוי משכנע נדרש לחקות את הגאומטריה הזו של האוזן.
כאן אתם בטח אומרים שכבר עשו זאת, אם באמצעות שתילת מיקרופונים באוזן האדם או יצירת ראש דמי (Dummy) שב'אוזניו' שתולים מיקרופונים. זה לא העניין כאן, וגם הוא אינו מושלם כי כל אחד שומע אחרת ולרוב נדרשות אוזניות כדי לשכנע עם אפקט כזה.
מה שעשו החוקרים במקרה הזה היא הפיכת מונו לסטריאו באמצעות רמזים ויזואליים (כמו שבן אדם עושה לפעמים), כך שאם לדוגמה מתקבל סרט וידאו עם סאונד מונופוני, מערכת למידת המכונה מנתחת מהיכן בתמונה מגיע הצליל ואז מעוות את דרגות העוצמה והזמן כדי להשיג את אפקט המיקום.
לדוגמה, תארו לכם ווידאו המציג הרכב שבו מנגנים מתופף ופסנתרן. אם המתופף ממוקם בצד שמאל של התמונה והפסנתר בציד ימין, באופן ברור אנו מניחים שהסאונד של כל כלי מגיע מאותו הכיוון, וזה מה שלמידת המכונה עושה, באמצעות שינוי מרכיבי הצליל כדי להתאים למיקום בתמונה את השמע המרחבי.
בהתאם נבנה בסיס נתונים רחב של דוגמאות למידה המוקלטות בצורה בינאורלית (שתי אוזניים מלאכותיות), אשר הוזנו למערכת הלמידה עם אלגוריתמים לפיענוח מהיכן הצליל מגיע, ובהתאם להפוך את סאונד המונו למרחבי או תלת מימד. התוצאה מרשימה ואפשר לצפות בה בווידאו הזה.
כאן מודגם ומשווה מצב של הקלטת מונו לפני ואחרי הפיענוח. זה אמנם לא מושלם כי החוקרים עדיין לא הצליחו להתאים לכל מאזין ויכולת הקליטה שלו (מה שקורה במציאות), אך מספיק מהווה עד קדימה בלמידת מכונה וממוקד לווידאו עם מוזיקה.
המחקר כאן.
גלו מבצעים מדהימים! לחצו כאן כדי לגלות את רבי המכר של Temu ולקבל את חבילת הקופון שלכם בשווי ₪400. קבלו חיסכון ללא תחרות בכל זמן ובכל מקום. אל תחכו - פעלו עכשיו וחסכו בגדול!




-
כלים וירטואליים, פלאגים - VST/iRE: VST ARSENAL 2024mixtrim: :headphones: העולם הדיגיטלי הקנה לנו מכשירי אפקטים ורוורב פיזיים... …לשרשור המלא אחרון
-
אקוסטיקה, סביבת עבודהאיטום לחדר של תופים במרכז לימודי נגינהשאול: אני יש לי מרכז לימודי נגינה ויש כמה חדרים של חוגים אני עכשיו עובר... …לשרשור המלא אחרון
-
קידום עצמיRE: Boketto - הרכב אינסטרומנטלי חדשacidhead: היה הרכב ישראלי אחר עם אותו השם …לשרשור המלא אחרון
-
SoundBoard - סאונד מקצועיRE: הסרת צלילי תופים מתקליט קייםRock_Artist: בפועל יש יחסית מעט מודלים קיימים שבהם משתמשים כולם. רוב המודלים... …לשרשור המלא אחרון
-



-
 הוירוס מאיץ את הכחדתה של המדיהאתרי תוכן נסגרים, עיתונים מודפסים כבר לא רלבנטים, ערוצי טלוויזיה בסכנה /pixabay.com/ … לכתבה :::
הוירוס מאיץ את הכחדתה של המדיהאתרי תוכן נסגרים, עיתונים מודפסים כבר לא רלבנטים, ערוצי טלוויזיה בסכנה /pixabay.com/ … לכתבה ::: -
 ה-Caustic 3.2 - מערכת DAW במכשיר האנדרואיד שלך
ה-Caustic 3.2 - מערכת DAW במכשיר האנדרואיד שלךCaustic 3 הינה מערכת הקלטה/הפקה למכשירי מובייל. היא כוללת מגוון כלים מוזיקלים כמו סינתסייזרים,
… לכתבה ::: Caustic 3
-
 המקליט של Google אינו עוד אפליקציית הקלטה
המקליט של Google אינו עוד אפליקציית הקלטהמגוון רחב של אפליקציות הקלטה לטלפונים קיים ברשת, אך לגוגל יש תכונה חזקה מאוד להציע
… לכתבה ::: Recorder by Google
-
 תן לצמחים שלך לנגן מוסיקה, וגן של צלילים יפרחמכשיר בשם PlantWave ממיר את המוליכות החשמלית של עציצי הבית לאודיו, ומעניק לצמחים אפשרות … לכתבה ::: PlantWave
תן לצמחים שלך לנגן מוסיקה, וגן של צלילים יפרחמכשיר בשם PlantWave ממיר את המוליכות החשמלית של עציצי הבית לאודיו, ומעניק לצמחים אפשרות … לכתבה ::: PlantWave
-
כתבה || הקלטות תופים - עצות ורעיונותהקלטת ערוץ התופים לשיר שלכם יכולה להיות אחת המשימות המאתגרות בתהליך ההקלטה, והחשיבות … לכתבה ::: הפורומים של אקט מוסיקלי
- » פורום סאונד ▮ הגברה
- » פורום אקוסטיקה ▮ בקרת צליל
- » פורום גיטרות ▮ בס ▮ מקלדות
- » פורום כרטיסי קול ▮ מחשבים ▮ VST פלגין
- » לימודים ומוסדות ▮ קידום עצמי וביקורת
- » פורום DJ ▮ מוסי' אלקטרונית
- » Cubase ▮ ProTools ▮ Logic
- » DIY אלקטרוניקה ▮ מדריכים ▮ בריאות